IBM Z Performance Management
Unlock Continuous Availability for your Application Infrastructure
Today’s global, 24/7 economy demands business applications to offer continuous availability (zero service disruptions), but a lack of critical visibility into and understanding of the IT infrastructure makes this difficult to achieve.
IntelliMagic Vision empowers mainframe sites to prevent service disruptions before they occur and utilize measurement data insights to lower costs and optimize business applications.

Lower Your Mainframe Costs and Optimize Your Application Infrastructure
Reduce Downtime
Automated site health and risk detection flags upcoming hidden bottlenecks, configuration errors and anomalies before symptoms hurt service levels or bring down applications
Lower Costs
Easily optimize your workloads and site configuration to lower CPU consumption. Rebalance workloads and applications to postpone or avoid new hardware purchases

Accelerate Training
Utilize an intuitive and interactive interface with built-in best-practice thresholds and recommendations to accelerate new hire and cross-platform training
Take Control of Your Mainframe with Interactive Insights and Customizable Reports
Risk Detection and Health Insights Automatically Summarize the Health of Your Entire System
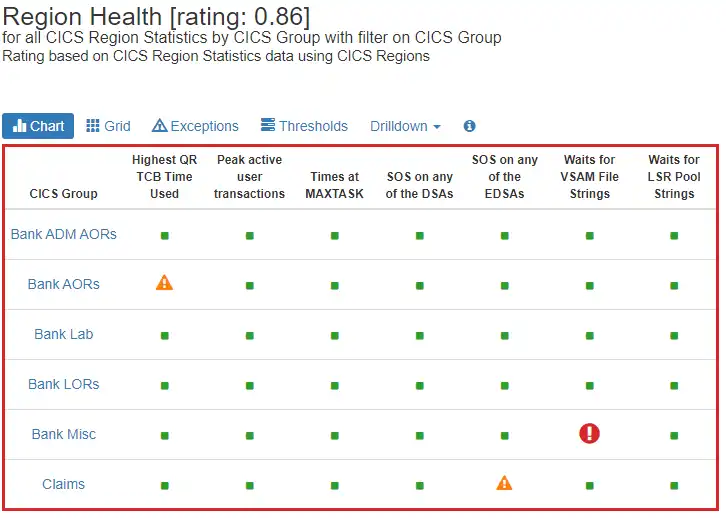
Prevent potential risks to availability and performance with built-in artificial intelligence automatically assessing more than 700 key z/OS metrics and using thresholds derived from built-in expert domain knowledge.
The easily consumable view shown here assesses the overall health of all CICS regions, leveraging user defined CICSGROUPs to enable exceptions from among hundreds of regions to be quickly identified and proactively addressed.
Automated z/OS Anomaly Detection and Statistical Analysis
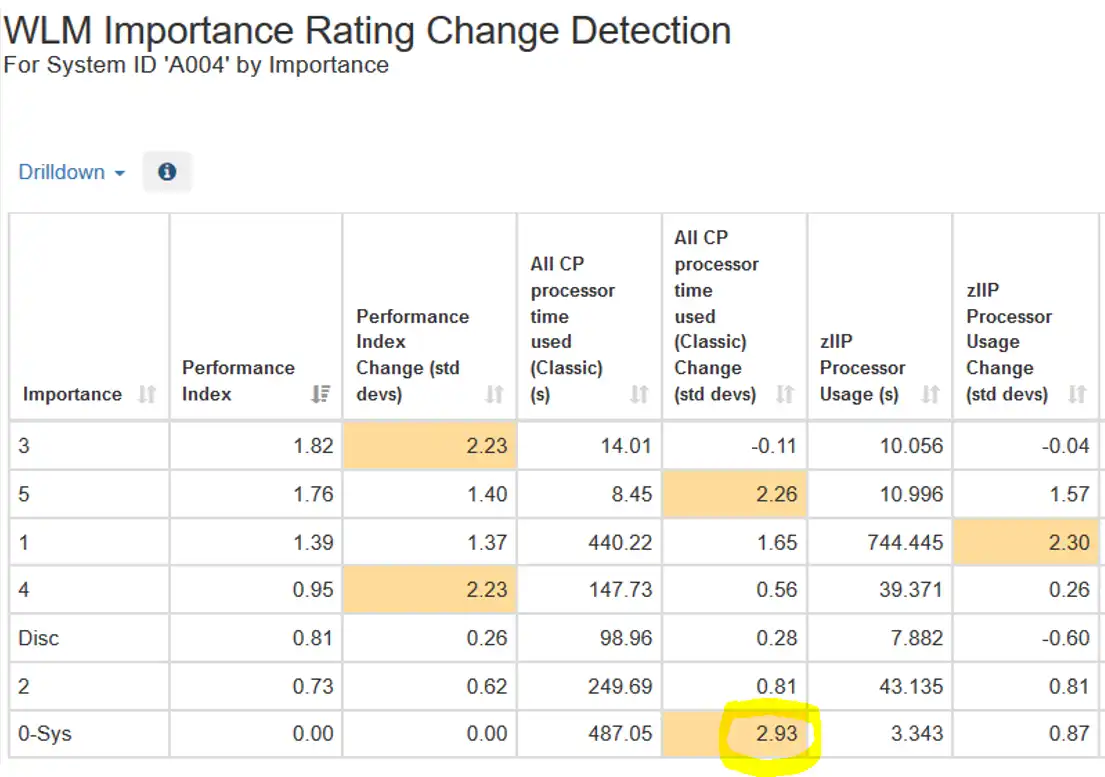
Statistically significant changes in key metrics are highlighted in Change Detection views. Variations that exceed + or – 2 standard deviations between the current day and the prior 30 days are highlighted.
This can enable you to get an early jump on changes that may have a sustained impact, such as this example of increased CPU consumed by highest dispatching priority System work.
Completely Interactive GUI with Intuitive Visibility into SMF Data
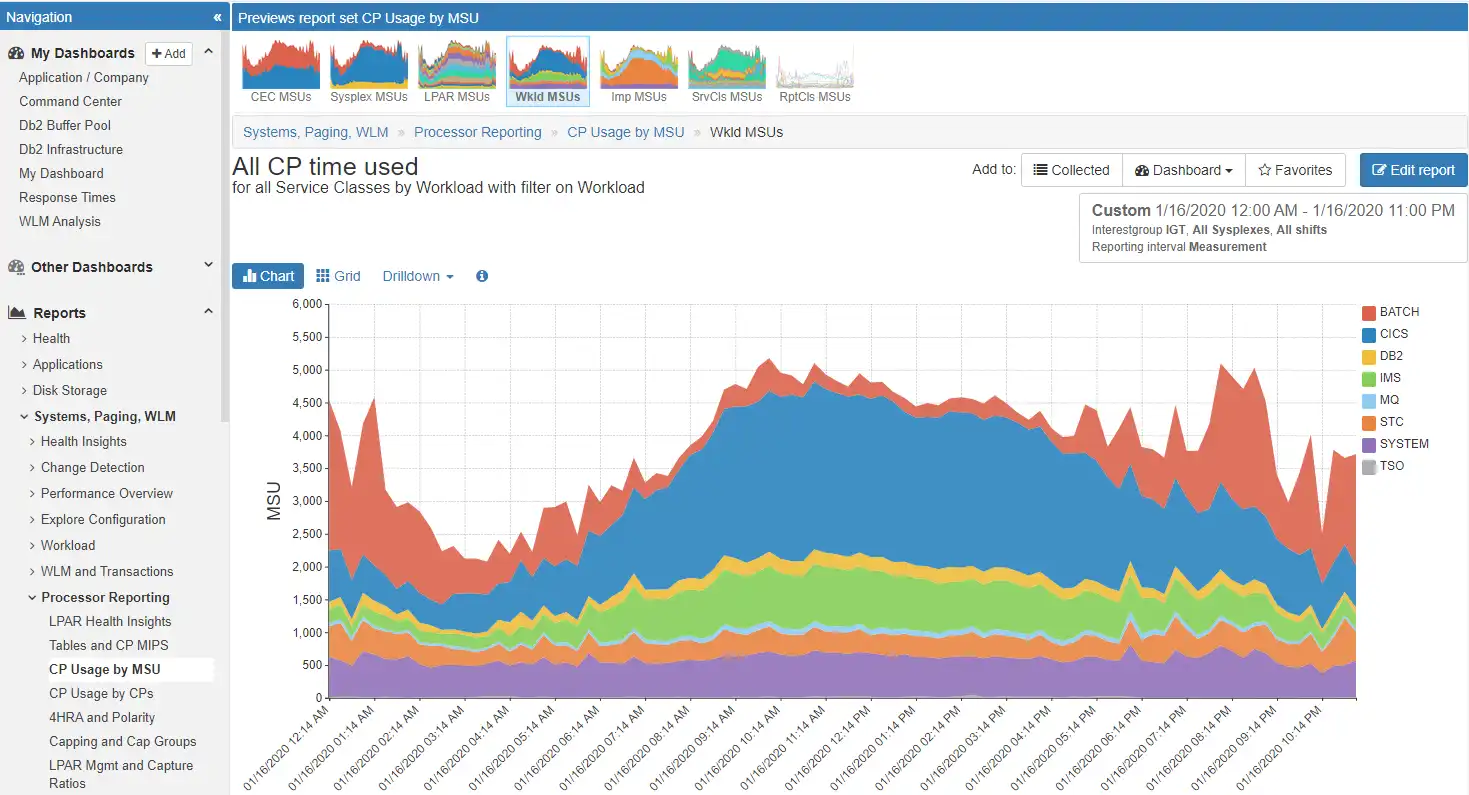
In contrast to approaches today that require coding programs or mastering tooling siloed by technology to access various types of SMF data, a common, intuitive user interface eliminates effort spent mining data and instead frees up staff to focus entirely on high-value analysis.
This single interface used across the entire z/OS platform greatly expedites learning, promotes collaboration, and enhances analytical effectiveness.
Dynamic Report Customization with Robust Editing Options
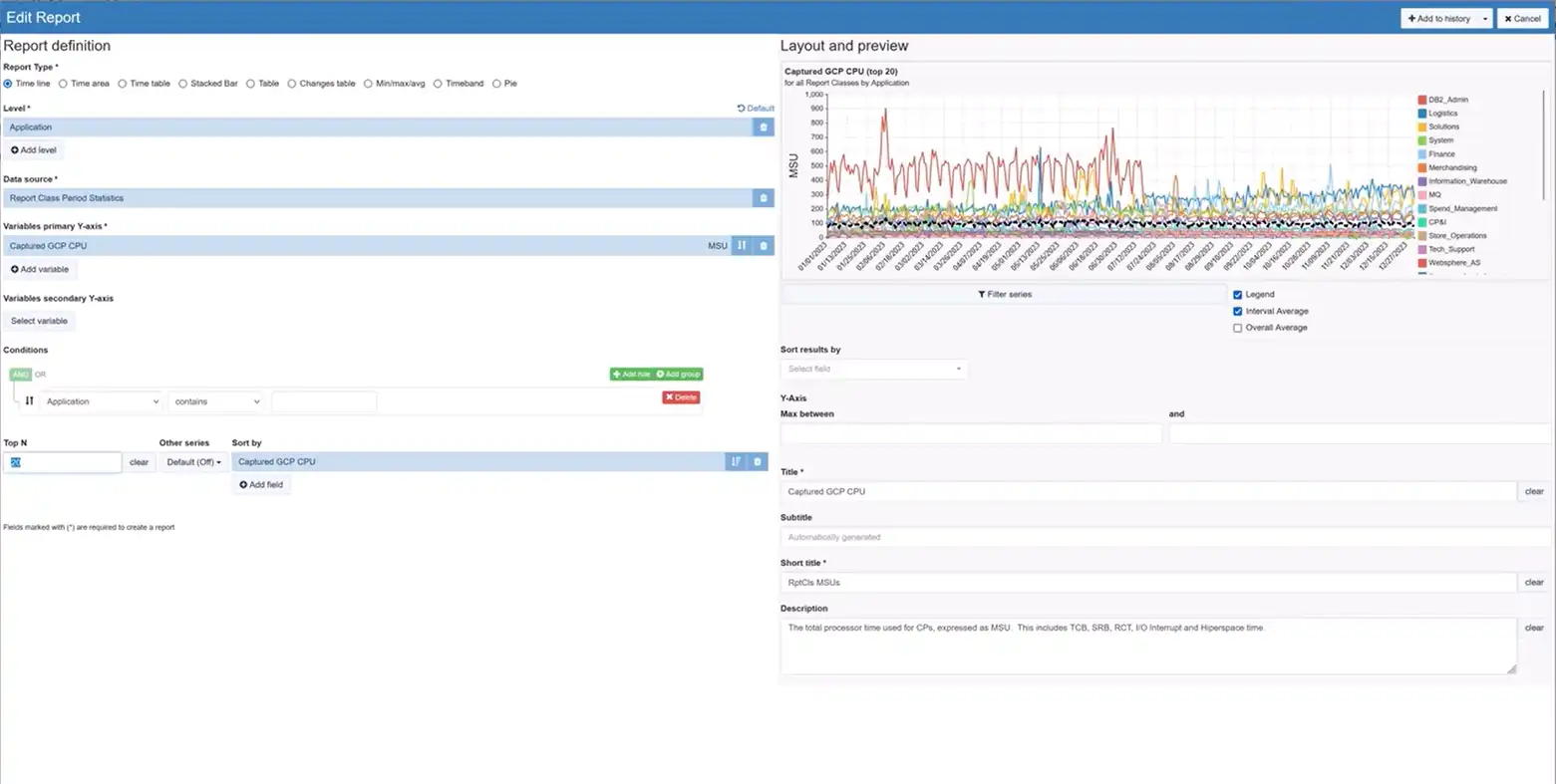
Advanced report customization capabilities facilitate quick ad hoc analysis without requiring programming or complicated steps and enable data to be viewed in the manner best suited to the current inquiry.
In this example, transaction rate is added to a response time chart to evaluate possible correlation. Numerous intuitive customization options including report type, summarization level, filtering, and interval comparisons.
Accelerate Problem Resolution with Context Sensitive Drill Downs
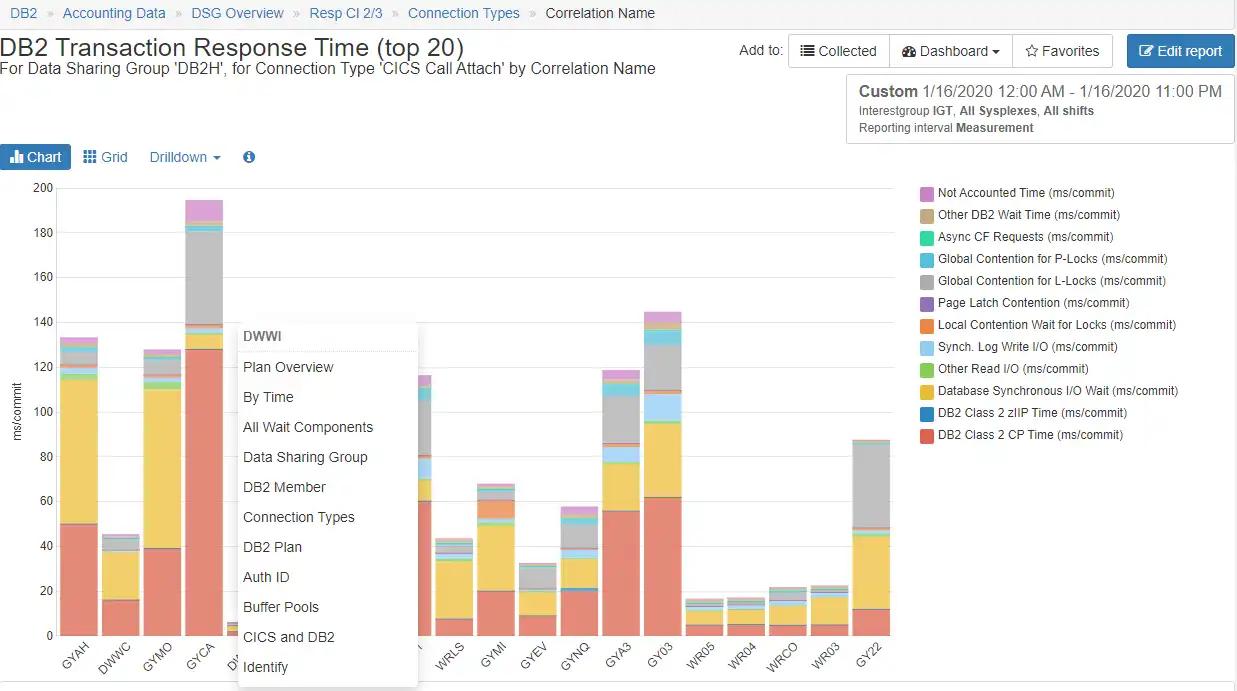
Context sensitive drill downs enable an analyst to identify alternative analytical paths based on the data currently being displayed and quickly investigate each hypothesis with just a few clicks, greatly reducing lost time when exploring what ends up being a “dead-end” path.
When dealing with massive SMF data volumes, this capability to focus analysis on the desired subset of data becomes especially valuable.
Easily Create, Share, and Export Customized Dashboards for Any Situation
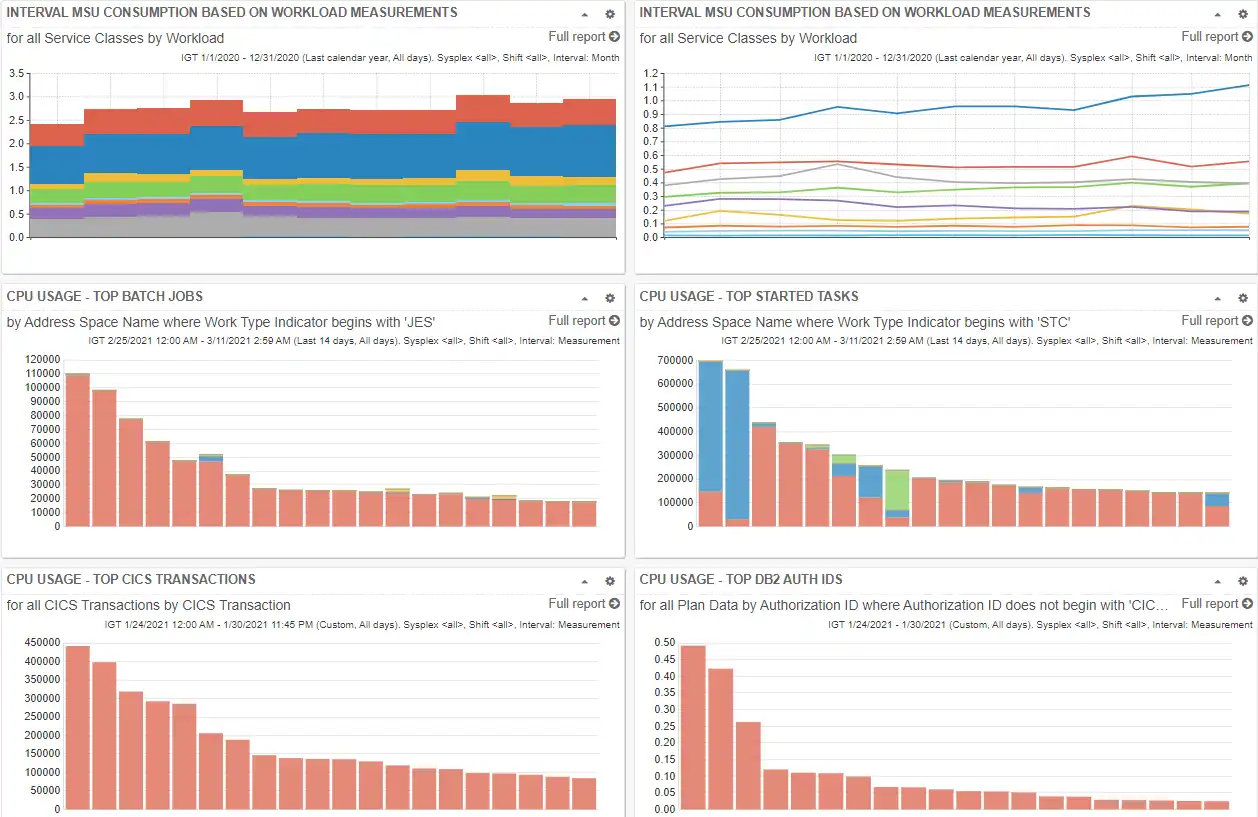
Customizable dashboards collect and display at a glance live views of any collection of reports and metrics of interest to you. When shared within your organization simply and securely via URL, they promote collaboration and provide a common truth for an entire organization.
Users can expand any report and leverage drill down capabilities to pursue further analysis of metrics they find of interest.
AIOps via SaaS Delivery
Advantages to adopting a cloud model include rapid implementation (no lead time to install and setup the product locally), minimal setup (only for transmitting SMF data), offloading staff resources required to deal with SMF processing issues or to install product maintenance, and easy access to IntelliMagic consulting services to supplement local skills.
Risk Detection and Health Insights Automatically Summarize the Health of Your Entire System
Prevent potential risks to availability and performance with built-in artificial intelligence automatically assessing more than 700 key z/OS metrics and using thresholds derived from built-in expert domain knowledge.
The easily consumable view shown here assesses the overall health of all CICS regions, leveraging user defined CICSGROUPs to enable exceptions from among hundreds of regions to be quickly identified and proactively addressed.
Automated z/OS Anomaly Detection and Statistical Analysis
Statistically significant changes in key metrics are highlighted in Change Detection views. Variations that exceed + or – 2 standard deviations between the current day and the prior 30 days are highlighted.
This can enable you to get an early jump on changes that may have a sustained impact, such as this example of increased CPU consumed by highest dispatching priority System work.
Completely Interactive GUI with Intuitive Visibility into SMF Data
In contrast to approaches today that require coding programs or mastering tooling siloed by technology to access various types of SMF data, a common, intuitive user interface eliminates effort spent mining data and instead frees up staff to focus entirely on high-value analysis.
This single interface used across the entire z/OS platform greatly expedites learning, promotes collaboration, and enhances analytical effectiveness.
Dynamic Report Customization with Robust Editing Options
Advanced report customization capabilities facilitate quick ad hoc analysis without requiring programming or complicated steps and enable data to be viewed in the manner best suited to the current inquiry.
In this example, transaction rate is added to a response time chart to evaluate possible correlation. Numerous intuitive customization options including report type, summarization level, filtering, and interval comparisons.
Accelerate Problem Resolution with Context Sensitive Drill Downs
Context sensitive drill downs enable an analyst to identify alternative analytical paths based on the data currently being displayed and quickly investigate each hypothesis with just a few clicks, greatly reducing lost time when exploring what ends up being a “dead-end” path.
When dealing with massive SMF data volumes, this capability to focus analysis on the desired subset of data becomes especially valuable.
Easily Create, Share, and Export Customized Dashboards for Any Situation
Customizable dashboards collect and display at a glance live views of any collection of reports and metrics of interest to you. When shared within your organization simply and securely via URL, they promote collaboration and provide a common truth for an entire organization.
Users can expand any report and leverage drill down capabilities to pursue further analysis of metrics they find of interest.
AIOps via SaaS Delivery
Advantages to adopting a cloud model include rapid implementation (no lead time to install and setup the product locally), minimal setup (only for transmitting SMF data), offloading staff resources required to deal with SMF processing issues or to install product maintenance, and easy access to IntelliMagic consulting services to supplement local skills.
Game Changing Visibility into Your Entire End-to-End z/OS Infrastructure
zSystems Performance Management
Optimize z/OS Mainframe Systems Management with Availability Intelligence
Benefits
Optimize z/OS Systems performance management using AI-driven analytics to proactively monitor and manage your z/OS environment, prevent disruptions, reduce costs, and preserve the reliability and availability that mainframes are known for.
Explore z/OS Systems Performance Analytics
Db2 Performance Management
Prevent Availability Risks and Optimize Db2 Performance
Benefits
The volume and complexity of Db2 Statistics data and Db2 Accounting data creates a major challenge for analysts who want to derive value from the rich metrics available.
Easy visibility into key Db2 metrics through SMF records is crucial to proactively prevent availability risks and to effectively manage and optimize performance.
Explore Db2 Performance Analytics
Easy visibility into key Db2 metrics through SMF records is crucial to proactively prevent availability risks and to effectively manage and optimize performance.
CICS Performance Management
Monitor and Profile CICS Transactions and Regions with IntelliMagic Vision
Benefits
CICS SMF Transaction data is a rich source of performance insights, but its volume can make analysis challenging using traditional approaches that rely on static reports. Proactive assessment of key Statistics metrics across all regions is essential to identify potential risks to availability.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS CICS transactions more effectively and efficiently, as well as proactively assess the health of their CICS regions.
Explore CICS Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS CICS transactions more effectively and efficiently, as well as proactively assess the health of their CICS regions.
Virtual Tape Performance Management
Proactively Manage Virtual and Physical Tape Environments
Benefits
With tape virtualization, tape storage became easier and more economical, but at the same time, more difficult to understand which changes or hardware upgrades are the best choices. With tape libraries being shared across multiple z/OS images, the full picture can only be obtained by aggregating workload and tape hardware information from all z/OS LPARs.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Virtual Tape environments more effectively and efficiently.
Explore Virtual Tape Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Virtual Tape environments more effectively and efficiently.
Disk & Replication Performance Management
Automatically Detect Storage Performance Risks & Quickly Resolve Issues
Benefits
As Disk speeds and throughputs have increased, z/OS applications have come to rely on fast and consistent storage performance. To respond quickly to unexpected disk and replication issues, it is essential that you have insight into the health of the various components in your storage environment.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Disk and Replication environment more effectively and efficiently.
Explore Disk & Replication Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Disk and Replication environment more effectively and efficiently.
MQ Performance Management
Optimize and Analyze MQ Activity and Performance
Benefits
MQ is widely used across z/OS environments, but sites often find it challenging to derive the valuable performance insights potentially available from MQ SMF Statistics and Accounting data due to limitations in existing reporting and available tooling.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS MQ configurations and activity more effectively and efficiently, as well as proactively assess the health of their queue managers.
Explore MQ Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS MQ configurations and activity more effectively and efficiently, as well as proactively assess the health of their queue managers.
z/OS Network Performance Management
Automatically Monitor Mainframe Network Security and Protect Your Data
Benefits
TCP/IP is the core of the communication for the z/OS mainframe, both for traffic into and out of the mainframe and internal communication among z/OS images and processor complexes. Proper management is necessary to secure and protect system availability.
IntelliMagic Vision automatically generates GUI-based, interactive, IBM best-practice compliant rated reports that proactively identify areas that indicate potential upcoming risk to TCP/IP health, performance, and security.
Explore TCP/IP & zERT Performance Analytics
IntelliMagic Vision automatically generates GUI-based, interactive, IBM best-practice compliant rated reports that proactively identify areas that indicate potential upcoming risk to TCP/IP health, performance, and security.
z/OS Connect: Modern Mainframe API Environment
Optimizing Mainframe API Monitoring for Improved Resource Management
Benefits
IntelliMagic Vision enhances mainframe API monitoring and profiling, providing crucial visibility to address issues at the API or service level, ultimately aiding performance analysts in better resource planning and management reporting.
Explore z/OS Connect Performance Analytics
See Why IntelliMagic is Trusted by Some of the World’s Largest Mainframe Sites
Contact an Expert or Request a Custom Demo
Discuss your technical or sales-related questions with our mainframe experts today